SHARP 2016: Translating Networks
13 Aug 2016Below are the slides and (sort of) reconstructed text of a talk I gave as part of the “Status of Translators” panel at SHARP 2016 in Paris, July 19, 2016. Slides appear at the end.
Today I’m going to share some of the work we doing on our Translating Networks project. I’ll start with a short intro, the genesis and purpose of the project, then talk in more detail about the data work that we are doing and our preliminary research. I’ll conclude with ideas for next steps — some of which are in the planning stages, some perhaps more aspirational.
In The World Republic of Letters, Pascale Casanova argues that the relative importance of a “national” literature on the world literary stage depends not so much on the number of great writers in the language, as on the number of effective mediators from the original language to the target language.[1] This perspective calls for a methodology that considers world literature as a system, a system that is the work of many hands and that supersedes national boundaries. “Many hands” here implies not just a listing of names, but the delineation of a network of translators, original authors, publishers, places, institutions, prizes, and so on. With this in mind, Translating Networks seeks to explore and better understand the communities, connections, and influences in literary translation through graph theory while attempting to assemble a database that documents not just translated works and their bibliographic data, but the communities and conditions within which the translated works are created, disseminated, and evaluated. The project is also very much about exploring the application of network analysis and other computational methods to translation studies, as well as to book and publishing history research more broadly.
So, what are we doing right now? We are currently collecting new data through a variety of methods and enhancing the datasets with new facets and classifications (which I’ll get to in more detail). As we collect new data and expand on what we have, we are also exploring and analyzing the data as we go. This is helping us to further define our research questions and rethink the types of data we’d like to collect now and in the future. We’re also working toward building the infrastructure for a translation database platform. We are still in the research and planning stages on this one, but we have made a few decisions and some basic work is underway.
At the time of this paper, we were a team of four: Thomas O. Beebee, Professor of German and Comparative Literature at Penn State, and I began the project as an exercise in a Network Analysis workshop led by Elijah Meeks at HILT. After securing some funding from CHI, Tom recruited Penn State graduate student, Sean Weidman, to the project. Sean is adding more data about publishers, authors, and translators to the database and working along side Tom and I to think through data modeling issues and research questions. Earlier this summer Martin Klein, a data scientist in UCLA’s Digital Library Program, joined the team. Martin brings loads of experience using linked data to connect datasets to other datasets and is interested in how we can leverage graph databases in this type of project. This is probably a good time to emphasize the importance of the team in a project such a this one - each team member brings experiences, skills, and motivations that enrich the project and its outcomes - it also helps to spread the work around! No one person can do it all and we are all continually learning from one another.
Before diving into some of our preliminary findings, I’d like to talk for a few minutes about the data that we’re working with and our attempts to collect and enhance new datasets. The project began with Three Percent’s Translation Database. Three Percent is a resource for international literature at the University of Rochester. In 2008 they began collecting data on original translations of fiction and poetry published or distributed in the United States. The database includes titles, authors, translators, publishers, dates, and genre for the years 2008 to 2016. To supplement the Three Percent spreadsheets, we’ve started harvesting data about authors, translators, and publishers from sources such as DBPedia, the Library of Congress, and VIAF - each of these with varying degrees of success. In a side note, this data harvesting is also highlighting the marginal position of translators in the publishing record. Of course this comes as no surprise, but we are taking note of how rare it is to find a translator listed in a DBPedia record, even rarer to find a translator field that is an access point or link to the translators own record. In addition to harvesting data, we are working to manually enhance the existing data. So far we’ve added gender and nationality where possible, whether or not the translation is of contemporary or older work, and whether or not publishers are focused on translation.
Other enhancements to the data require us to define or codify aspects of our entities. For example, we are interested in looking at correlations by publisher types, so we’ve defined five publisher types and assigned to our publishers accordingly. We are also interested in defining translator types — some translators are scholars, some are poets or writers in their own right, and some are lucky enough to make their careers out of literary translation. Other facets we are hoping to add include retranslations, scholarly vs. popular reading translations, and institutional affiliations.
Now, a bit of background. Our project humbly began as an exercise in network analysis. Tom and I were participating in a week-long network analysis workshop at HILT and it happened that I had the Three Percent spreadsheets on my laptop. We went to work organizing our data, creating node and edge lists, learning about Gephi, and familiarizing ourselves with the various types of centrality in a network. It did not take long for themes and communities to emerge from our data, narratives that reinforced what we already knew or suspected about contemporary translation communities (gender, big players, and so on). Right away we began lamenting the lack of dimension in our dataset. We were missing key data that would help us get at those underlying, less obvious narratives - those questions we now wanted to explore in more detail. It was decided then that we would begin a small “project” and that we’d need to beef up our data.
While planning our approach, we first considered questions on the historical and typological nature of translation communities. What is the makeup of a particular translation community? And how might they differ between Original Language communities? How do communities change over time? Most of the data collected and our enhancements revolved around the translated texts, but we wondered how far could / should we look beyond the texts? As Hoyt Long put it, how might we capture data on “ideological forces, social relations and institutions, and the expanding systems of circulation, diffusion, and influence”?[2]
In addition to the questions about the subject matter (translation communities), I also became very interested in how we might “operationalize” the research (a term from Franco Moretti)[3] – how we might use computational methods to help bridge the gap between literary theory and texts - moving back and forth between concept and measurement. Moving forward, we will explore both the historical and typological nature of translation communities - how these communities have changed over time and what factors define, influence, and characterize these networks, as well as how methods like network analysis are applied and applicable to book and publishing history more broadly.
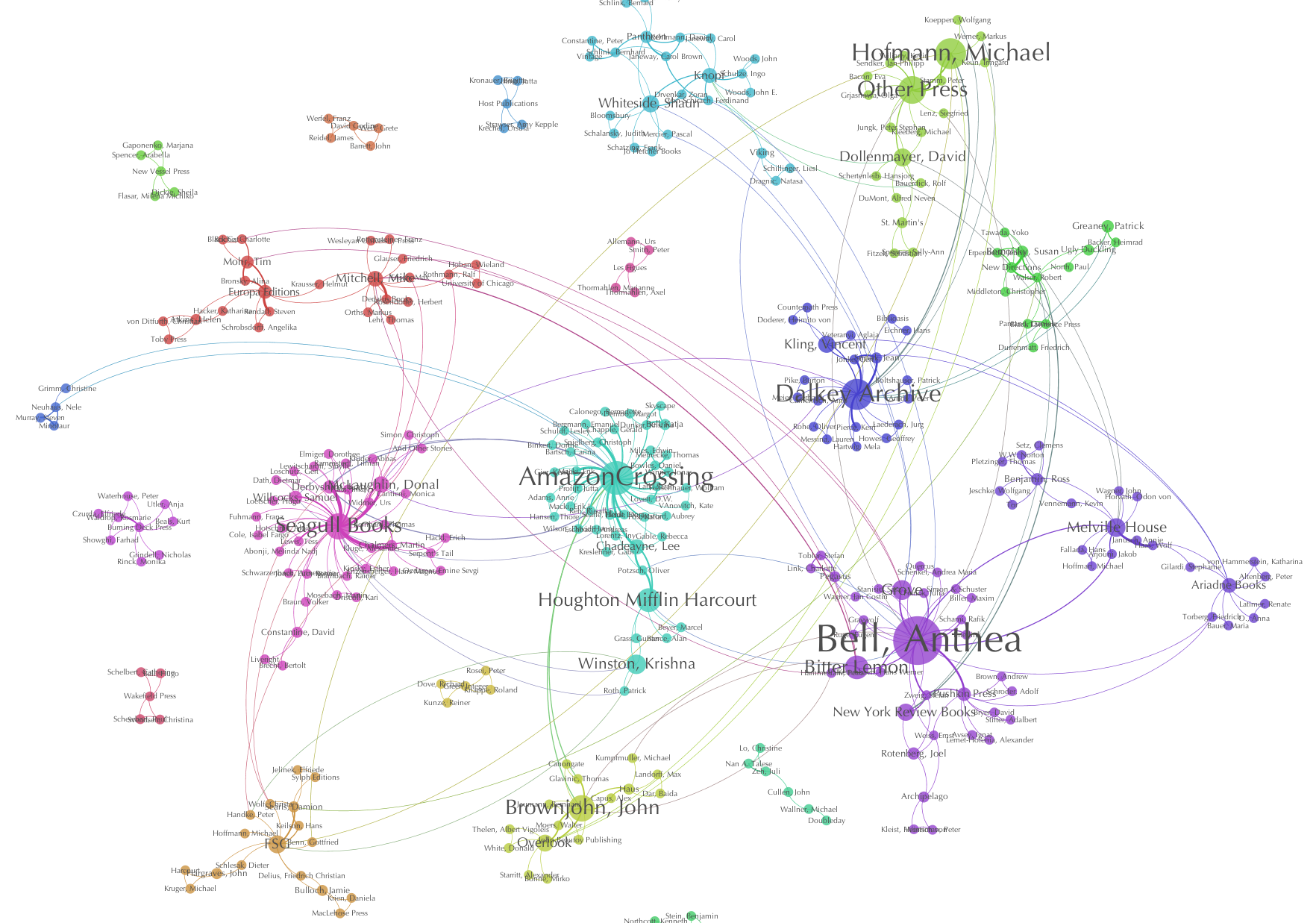
Now we’ll look at some of our initial graphs. In our first graph [German translation communities, 2008-2014] we can see a number of discrete communities forming, sometimes around publishers, in some cases around translators. To detect communities we use “modularity”. From wikipedia: “Modularity measures the strength of division of a network into modules. Networks with high modularity have dense connections between the nodes within modules, but sparse connections between nodes in different modules.” We can also see that some nodes are much larger than others in this graph. The larger the node, the more they can be said to have “betweenness centrality”. This type of measurement helps us to determine potential important players in a network. Again, from Wikipedia: “Betweenness centrality is an indicator of a node’s centrality in a network. It is equal to the number of shortest paths from all vertices to all others that pass through that node.” - in other words, these nodes can potentially function as “bridges” in a network.
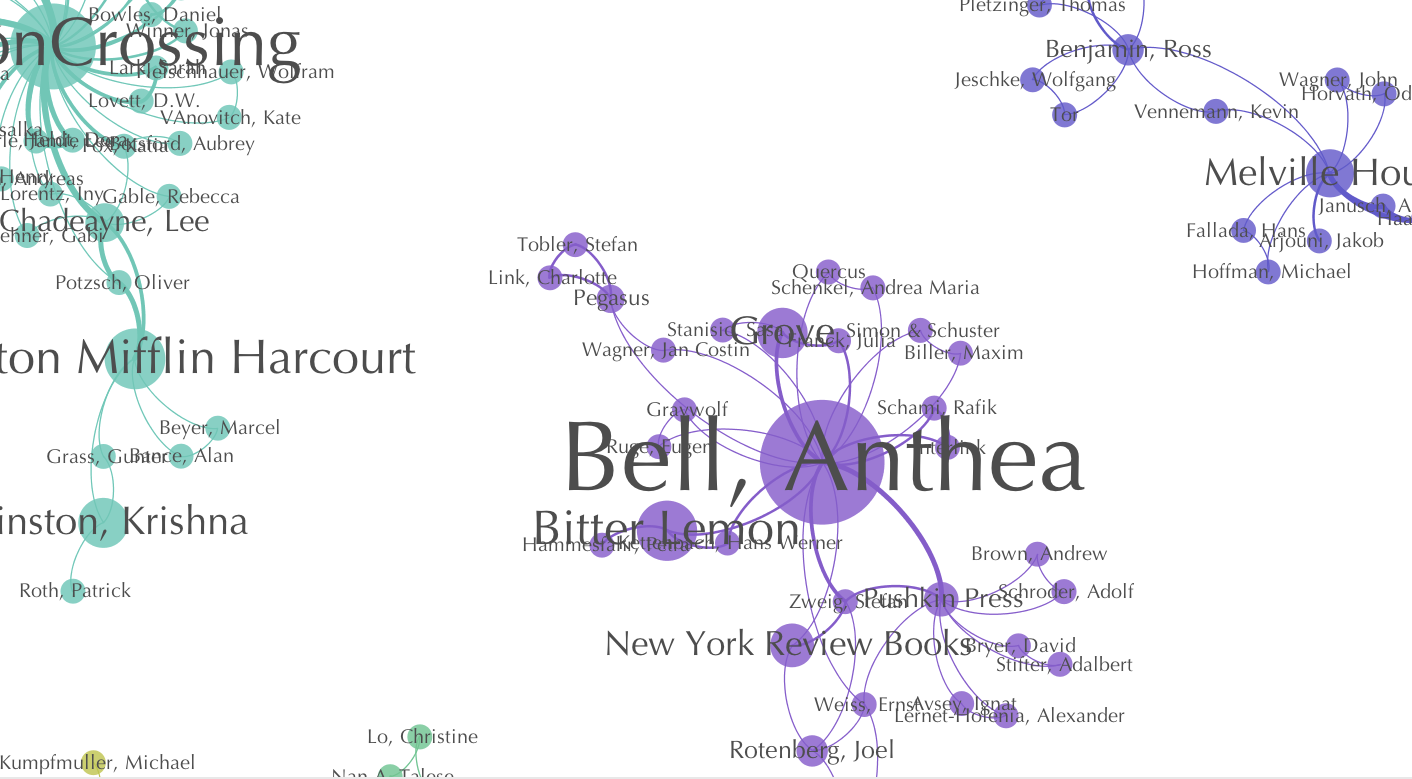
Let’s zoom in a little. In this graph [German translation communities, 2008-2014, zoomed], most of our detected communities center around a publisher with a higher betweenness centrality, like we see here with Amazon Crossing; but we also see a few translators that dominate their part of the network, like Anthea Bell. We’re hoping that the data we collect on publisher and translator types will allow us to zoom in on these relationships and discover patterns that provide further insight into the make-up and nature of translator dominated-communities vs. publisher-dominated ones. We are noticing that within some language groups there are larger numbers of individuals with high betweenness centrality, while some others tend to be dominated by publisher defined communities. This is not necessarily surprising, but will get a closer look as we enhance the data. **It’s also important to note that high betweenness centrality is a measure of the “potential” for serving as a bridge or conduit for transmission; the degree to which this position in the network is leveraged is another matter[4].

In this next graph [German publisher single-mode network], we’ve taken the German translation communities graph above and collapsed the author and translator “nodes” into the edges, creating a publisher single-mode network. Leaving the original communities intact, we can see the Anthea Bell community comprises small press publishers which retain their many network connections to one another. In contrast, our Amazon Crossing community, despite having the highest number of publications and edges, is fairly isolated when you collapse the authors and translators into our network edges.
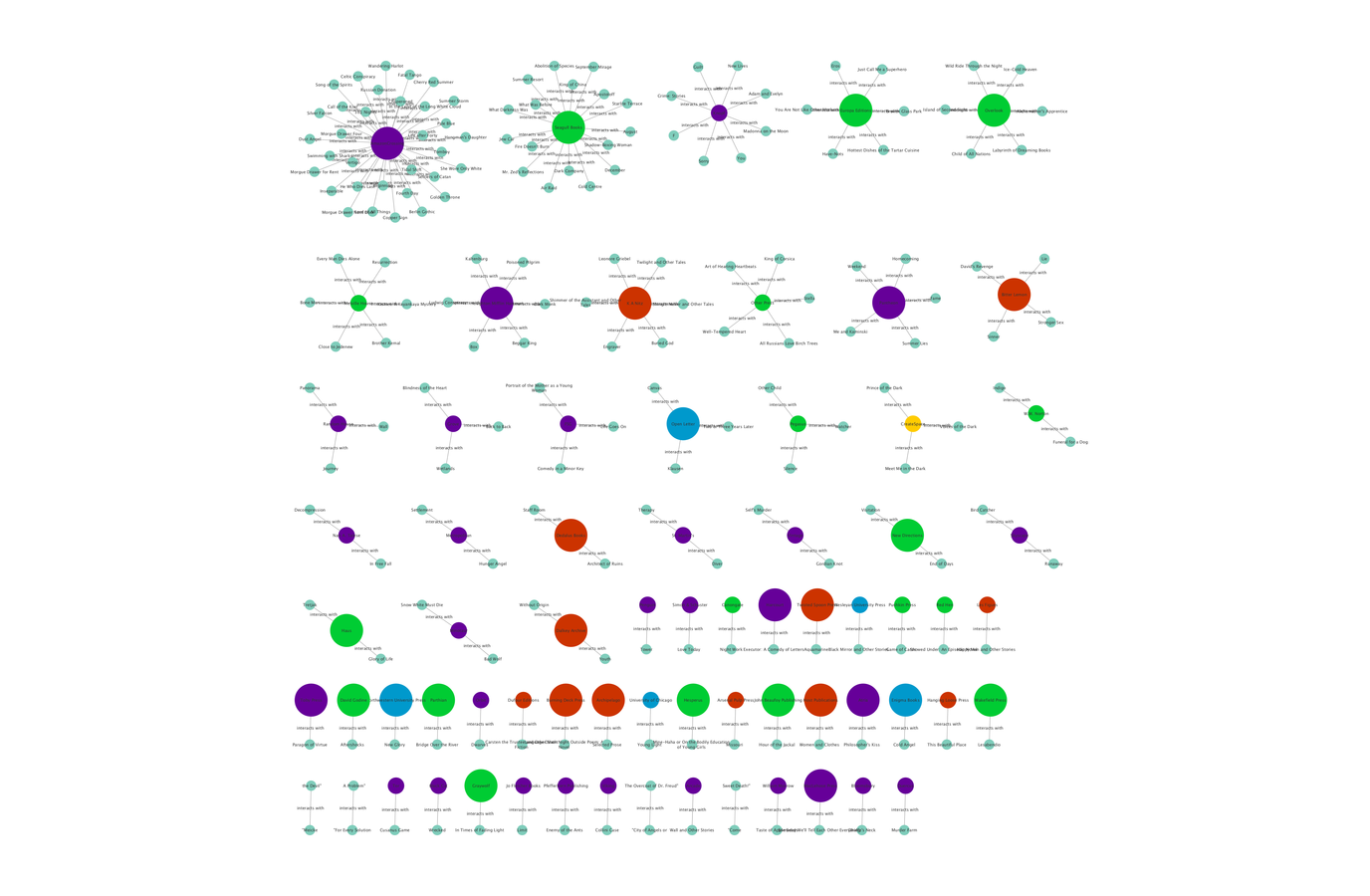
Our final graph [German publishers by focus on translation] shows which publishers have a focus on translation by our “ publisher type” category. The publisher types are color coded — blue is academic, green is independent, yellow is self-publishing, red small press, and purple is trade. The larger node size denotes a focus on translation. I just want to reiterate: the current data represents a simple publishing record, network connections are defined by transaction and do not necessarily reflect influence or importance. The detected communities we are seeing are bound together by the publishers that accept manuscripts, or in some cases by well-known translators. Some questions we have: Do the entities with higher centrality scores make use of their position? What are other points of contact (besides publishers) that influence or bind a translation community together? Do different translators tend to associate with different venues exclusively, or do they cross over? Do certain authors or translators play the role of “broker” between translational small worlds? These initial questions are driving the current data collection and enhancement, but digging through this data will of course result in new questions and new directions for data collection.
To hold all this new data that we are collecting, we’re building an open database. Currently we’re experimenting with a graph database model, specifically Neo4j. With a graph database, scholars will have more flexibility in how they query or visualize the data and it should be easier to further define and add more nodes and relationship types over time. We will also be experimenting with graphical interfaces for exploring the data within. Our hope is that with these interfaces, users will be able to explore data as an interactive visual network as well as contribute to and / or query the data. I also like to think that, in addition to the platform and dataset, we are building two things: 1) a network of scholars and technologists interested in exploring translation communities; and 2) a praxis-based project for researchers and students who want to learn about theories of literary communities, network analysis, databases & ontologies.
Moving forward, we will continue to focus on analysis and publication and continue to enhance our existing data. We also plan to expand the temporal scope of the project backward and to other time periods (say, Early Modern). The current dataset is limited to monographs, so we hope to include translations in journals and other serial forms. For our translators, authors, and publishers, we are looking at how we can collect and capture data about memberships and affiliations, such as academic institutions, translation organizations, and scholarly societies. We may also begin looking into circulation statistics, sales, appearance on reading lists, reviews, prizes, and so on. Our biggest hope, however, is that we will be able to open the project to scholar-sourcing of data in the near future. We welcome researchers interested in working with this data to participate in defining scope, collecting data, and using the data and platform for their own research. We, of course, extend this invitation to the international community. Partnering with international researchers to add data about the authors, translators, and publishers of works translated into languages other than English is our ultimate goal — the international context will be key to the long-term success of the Translating Networks project.
View the slides in full-screen here: https://dawnchildress.com/presentations/sharp16/#/
- Casanova, Pascale. The World Republic of Letters. Cambridge, Mass.: Harvard University Press, 1999.
- Long, Hoyt. “Fog and Steel: Mapping Communities of Literary Translation in an Information Age. The Journal of Japanese Studies, Volume 41, Number 2, Summer 2015, pp. 281-316.
- Moretti, Franco. “‘Operationalizing’: or, the Function of Measurement in Modern Literary Theory,” Literary Lab Pamphlet 6 (December 2013)
- This came from Scott Weingart, but I cannot remember in which of his blog posts I found this.